ZFNet¶
AlexNet에 이어 2013년에는 ILSVRC에서 Matthew Zeiler (뉴욕대 박사)가 Clarifai로 11.7% 에러율로 우승했다. 하지만 Clarifai에 대한 자료가 없고, Zeiler가 발표한 다른 CNN 모델인 ZFNet은 잘 소개 되어 있다. 같은 연구자가 만든 모델이기 때문에 Clarifai와 같은 흐름일 것으로 추정된다.
Zeiler는 뉴욕대에서 CNN을 더 잘 이해할 수 있게 하는 Visualizing 기법을 최초로 개발했고, 이와 관련 내용을 “Adaptive Deconvolutional Network for Mid and High-level Feature Learning”에 발표한다. 또한, 2013년에 “Visualizing and Understanding Convoultional Networks”라는 논문 발표 후 ILSVRC에 참여하여 우승했다.
어떤 부분이 ILSVRC 2013에서 Clarifai를 우승시키게 만들었는지 ZFNet과 Visualizing에 대해 지금부터 알아보려고 한다.
ZFNet이란¶
CNN의 구조를 결정하는 Hyperparameter를 어떻게 설정할 것인지는 매우 중요한 문제다. 하지만 어떤 값이 최적의 조합인지 판단하기 어렵다. 그래서 이러한 문제를 Zeiler는 Visualizing 기법 을 통해 해결하려 했다. 앞에 언급한 것처럼 Visualizing에 대한 중요한 개념은 2011년에 발표했고, 2012년에 AlexNet의 결과를 Reference로 해서 Visualizing 기법이 효과적임을 입증했다.
이후 Zeiler의 Visualizing 기법을 기반으로 발전된 논문을 발표했고, 아래 두 논문이 대표적인 예이다.
Visualizing Convolutional Neural Networks for Image Classification, Danel Brukner, 2015
Delving Deep into Convolutional Nets, Ken Chatfield, 2014
결론적으로 ZFNet에서 새로운 구조를 제안하기 보다는 Visualizing 기법을 기반으로 AlexNet의 구조를 Hyperparameter를 변경하여 성능을 더 개선 시킬 수 있음을 보였다고 할 수 있다.
Visualization¶
CNN의 큰 흐름은 “Feature map → Convolution (by filter) → Activation → Pooling” 과정의 반복이라고 할 수 있다. Visualizing은 기법은 중간 Layer의 값을 확인하여 학습이 잘 되고 있는지 확인하는 방법이고, 그래서 위 순서의 반대 작업을 했을 때 Convolution 각 Layer에서 어떤 값을 가지는지 이해할 수 있다.
아래 이미지가 Convolution과 Deconvolution 과정을 나타내고 있고, Deconvolution은 크게 Unpooling → ReLU → Deconvolution 3단계 로 나누어 볼 수 있다.
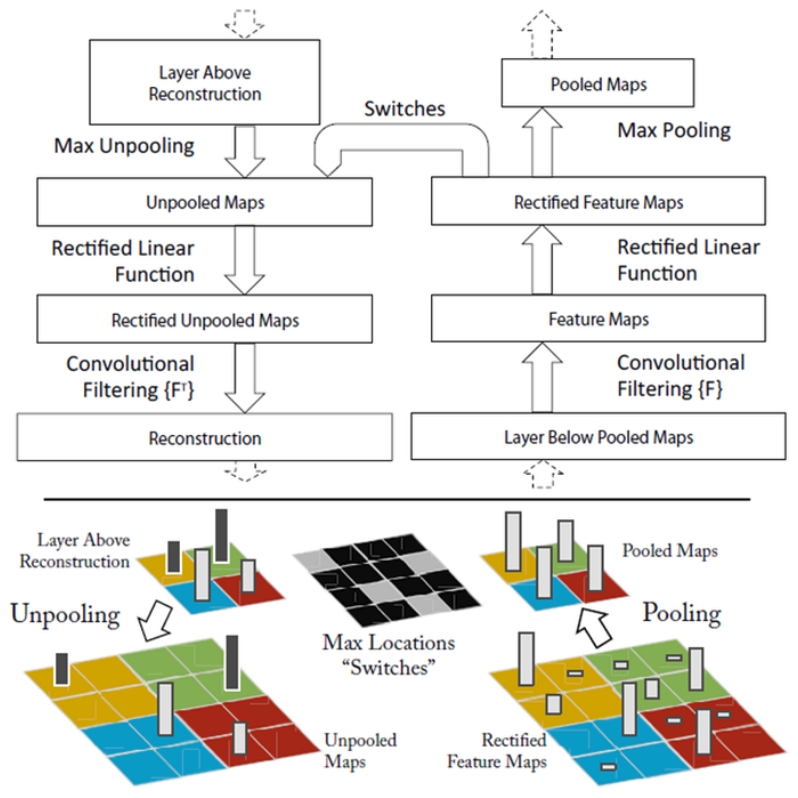
Unpooling¶
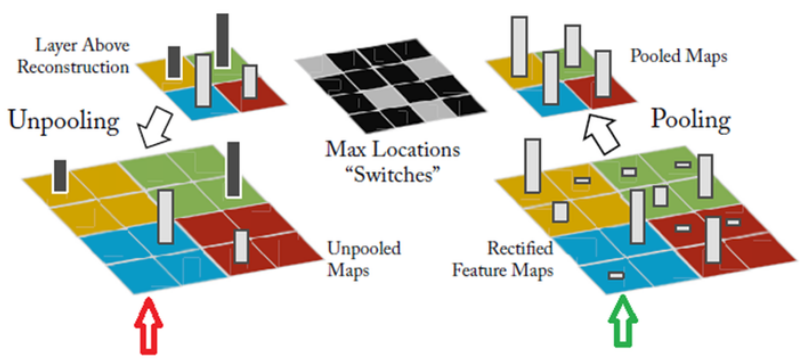
Max pooling에서 강한 자극만 전달되기 때문에 반대로 진행 시 그 위치를 알기 어렵다. 그래서 ZFNet에서는 강한 자극의 위치를 Flag 형태로 저장하여 Unpooling 시 활용했다. 하지만 이 방법의 단점은 약한 자극의 영향력은 알 수 없다는 점이다. 아래 그림이 Unpooling 과정을 잘 나타내고 있다.
ReLU¶
ReLU를 통해 음수 값은 모두 0으로 변경되어 되돌릴 방법이 없다. 하지만 Zeiler 팀은 연구 결과에 따르면 그 영향이 미미하다고 언급했다.
Deconvolution¶
마지막으로 Weight 값을 Transpose하여 Deconvolution을 실시하면 강한 자극이 어떻게 구성되어 있는지 확인할 수 있다. 예를 들어 4x4 Input image를 3x3 Kernel (= Filter)로 Convolution 한다고 했을 때 (Stride: 1, Padding: 0), 아래의 그림과 같이 표현할 수 있다.
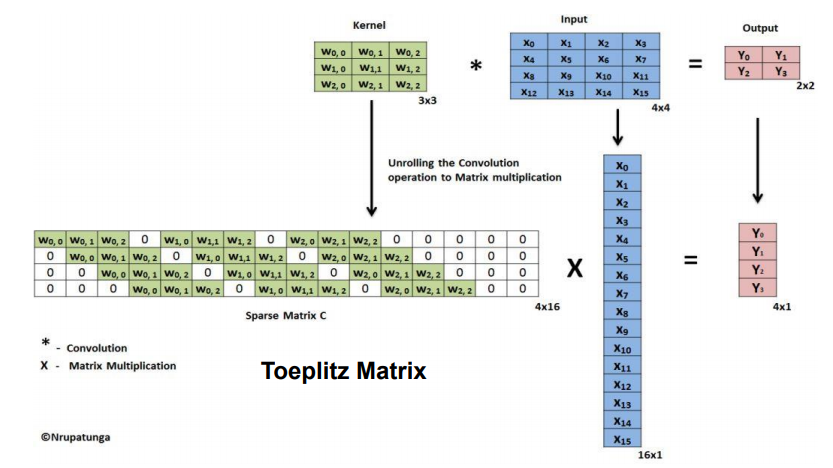
출처: 분석벌레의 공부방, [신경망] 18. Deconvolution
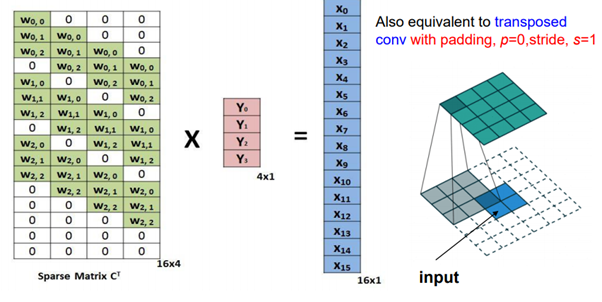
따라서 Input은 Output에 Sparse Matrix C를 Transpose한 행렬을 곱해 구할 수 있고, 이것이 Deconvolution이다. 자세한 Deconvolution 방법은 YouTube, 최희정 - CNN Localization (ZFNet & Deep Taylor Decomposition) 에서 확인할 수 있다.
Visualization results¶
지금부터는 위 과정을 통해 Visualization한 결과를 보려고 한다. ZFNet은 AlexNet처럼 5개의 Convolution layer를 가지고 있고 여기서는 각 Feature map의 가장 강한 특징 9개를 시각화 한 결과 를 보여주려고 한다.
Layer 1 and 2¶
Layer 1이나 2에서는 이미지의 코너, Edge, Color와 같은 Low level feature 를 보여준다.

각 Layer를 조금 더 살펴보자.
Layer 1¶
아래 그림의 왼쪽은 AlexNet이고, 오른쪽은 ZFNet이다. ZFNet에서는 AlexNet의 Stride (4 → 2)와 Filter (11x11 → 3x3)의 크기를 바꿨고, 그림을 보면 ZFNet의 결과가 훨씬 더 다양한 Feature를 검출할 수 있다는 것을 알 수 있다.


Layer 3¶
Layer 3에서는 Layer 1이나 2에 비해 더 복잡한 항상성 (Invariance)이나 비슷한 외양 (Texture) 을 가진 특징이 추출된 것을 볼 수 있다.

Layer 4 and 5¶
Layer 4에서는 사물이나 개체의 일부분 을 볼 수 있고, Layer 5에서는 위치나 자세 변화 등까지 포함된 사물이나 개체의 전부 를 보여준다

Layer 5를 조금 더 자세히 살펴보면, Edge나 Junction 같은 Low-level feature가 아닌 개 형태나 일부를 확인할 수 있다.

Architecture¶
ZFNet은 AlexNet과 달리 하나의 GPU를 사용했고, 70 epoch으로 12일 동안 학습시켰다. ZFNet은 Visualizing에 집중하여 구조는 AlexNet과 비슷하다.
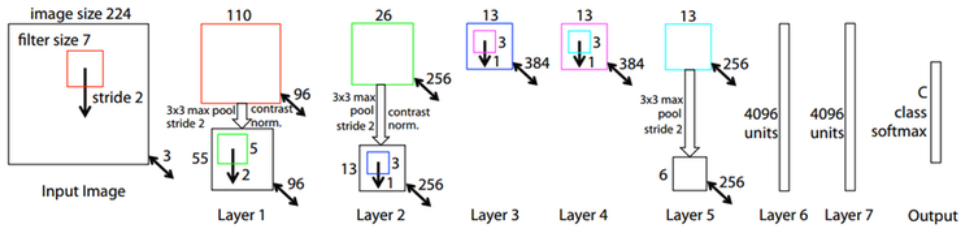
하지만, 구조적으로 다른 부분이 있다. 먼저, Layer 1과 Layer 2의 차이를 먼저 설명하려고 한다.
Layer 1, 2¶
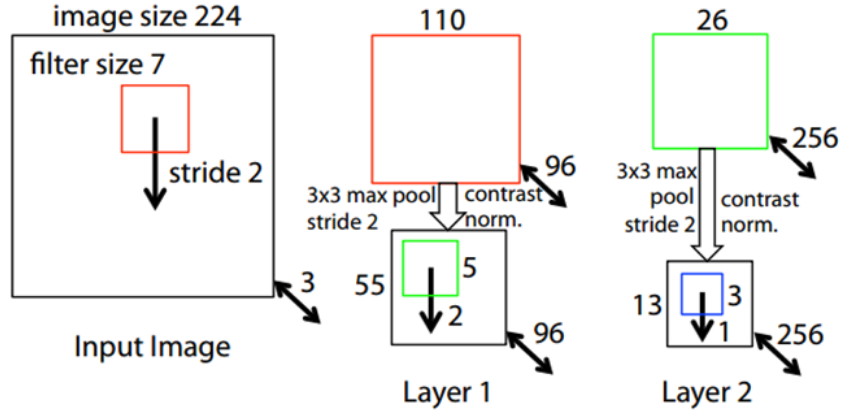
위 그림에서 알 수 있듯이 AlexNet과 ZFNet은 Layer 1과 Layer 2에서 구조의 차이를 보인다.
Model |
Layer 1 |
Layer 2 |
|---|---|---|
AlexNet |
11x11 Filter, Stride 4 |
5x5 Filter, Stride 1 |
ZFNet |
7x7 Filter, Stride 2 |
3x3 Filter, Stride 2 |
Visualization results에서 이미지 로 확인했던 것처럼 Filter와 Stride 크기를 줄였을 때, 조금 더 선명하고 다양한 Filter를 얻을 수 있었다. 그리고 요즘 추세에 따르면 Filter와 Stride의 크기가 큰 경우 성능이 좋지 못하다. Zeiler는 Feature visualization으로 AlexNet 구조를 변형시키면서 이를 증명했다.
Layer 3, 4, 5 and Layer 6, 7¶
다음으로 Layer 3, 4, 5를 살펴보자. 다음 이미지는 Layer 3, 4, 5와 Layer 6, 7의 Parameter를 변경하며 테스트한 결과이다.
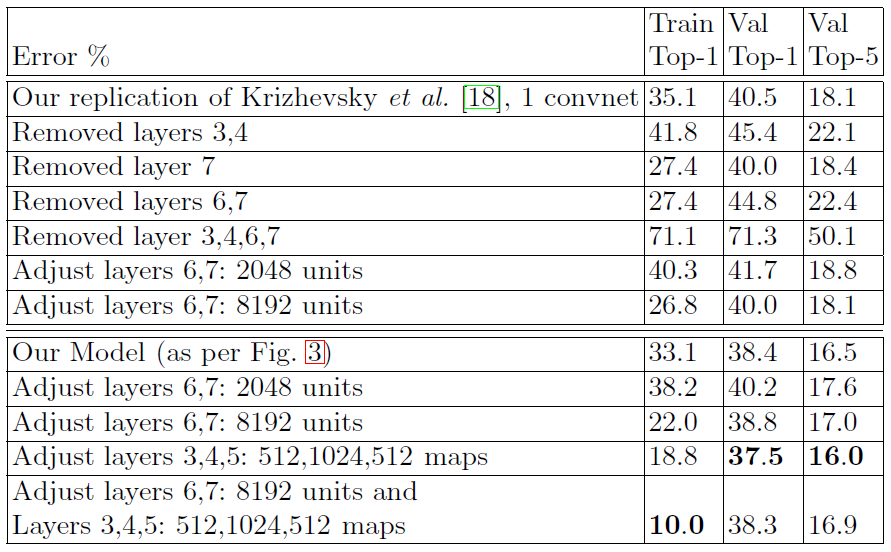
ImageNet 2012 classification error rates with various architectural changes to the model of Krizhevsky et al.¶
출처: Visualizing and UnderstandingConvolutional Networks
여기서 Our Model은 Layer 1, 2가 변경된 것을 설명할 때 사용한 이미지의 Model을 말한다. Layer 3, 4, 5의 Size를 각각 384, 384, 256에서 512, 1024, 512로 변경했을 때 결과가 더 좋게 나옴 을 확인할 수 있다. 하지만 Layer 3, 4, 5와 Layer 6, 7 (FC layer)를 동시에 크게 했을 때는 Overfitting이 발생해 성능이 더 낮게 나옴을 볼 수 있다.
GPU¶
AlexNet에서 2개의 GPU를 사용하기 위해 인위적으로 만든 구조를 제거하고 하나의 GPU 로 학습시켰다. 그 결과 Layer 1, 2의 Visualization 결과 처럼 ZFNet이 성능이 더 좋은 것을 확인했다. 이후에 GPU 2개에서 다른 처리를 시도하는 사례는 나오지 않았다.
최종적으로 ImageNet으로 테스트 했을 때, Top-5 error가 16.4% (수정 전)에서 11.7% (수정 후)로 줄었음을 확인할 수 있다.
Feature visualization으로 알게된 추가사항¶
Layer 별로 Feature를 습득하는 시간이 다름
앞쪽 Layer들은 몇 번의 Epoch만에 Feature들이 수렴함
뒷쪽 Layer들은 40 ~ 50 Epoch 이상에서 Feature들이 수렴함 (ZFNet: 70 epochs)

Concolusion¶
이처럼 Visualizing을 하면 각 Layer의 Feature map들의 분포 (고름 또는 편향됨)를 알 수 있고, 개체의 위치, 자세 등을 파악할 수 있기 때문에 적절한 Hyperparameter로 학습되었는지 판단할 수 있다.
