GoogLeNet¶
GoogLeNet은 2014년 ILSVRC에서 1위를 차지한 모델이고, 가장 큰 변화는 Network의 깊이다.
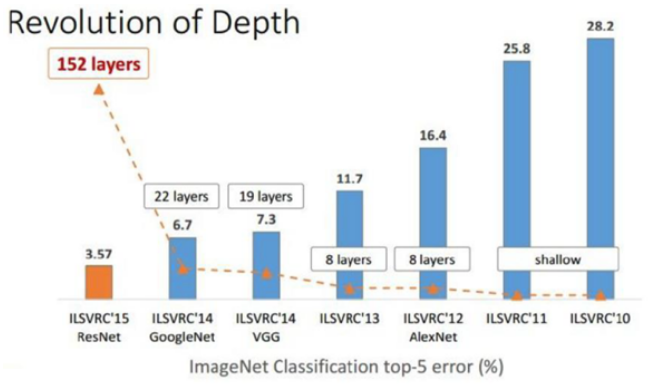
Convolutional Neural Network (CNN)의 성능을 향상시키는 가장 직접적인 방법은 Network 크기를 늘리는 방법이다. 2013년까지는 CNN network의 깊이가 10 미만이었지만, 2014년 GoogLeNet과 VGGNet이 각각 22 layer, 19 layer로 2배 이상 커졌다. 물론 Top-5 에러율도 각각 6.7%, 7.3% 낮아졌다. 이후 2015년에 우승한 ResNet은 152개의 Layer를 가지고 Top-5 에러율도 3.57%로 더 낮아진다.
하지만 Network가 깊어지면 Trainable parameter 수가 증가하게 되고, 그 결과 Overfitting 문제가 발생하거나 연산량이 급격히 늘어날 수 있다. AlexNet만 보더라도 Trainable parameter 수가 6천만개이고, GPU (GTX580) 2개를 사용하여 일주일 이상 학습시켰다. 단순히 Network를 깊게 만들면 학습시간이 엄청나게 길어질 수 있다.
따라서, 이러한 문제를 해결하기 위해서는 Network의 구조적인 변화에 대한 고민이 필요했고, Google에서 Inception이라는 모듈로 구성된 GoogLeNet으로 이를 해결했다. 자세히 살펴보기 전에 GoogLeNet이 이전 CNN 모델과 다른 Contribution이 뭔지 먼저 살펴보자.
Contribution¶
GoogLeNet의 Contribution은 다음 3가지이다.
Inception 모듈
1x1 Convolution → Parameter 수 감소 (AlexNet보다 12배 적음)
Convolution의 병렬적 사용
Auxiliary classifier
Vanishing gradient 문제 해결
우선 먼저 Inception 부터 시작해보자.
Architecture¶
이전에 언급한 것처럼 GoogLeNet은 Inception 이라는 모듈로 구성되어 있다. Inception 모듈은 Network는 최대한 Sparse하게 실제 연산에 사용하는 Matrix는 최대한 Dense하게 만들고자 하면서 만든 구조다. 또한, Inception 모듈은 싱가포르 국립대학의 Min Lin이 2013년에 발표한 “Network in Network”의 구조를 더 발전시킨 형태 이다.
지금부터 하나씩 살펴보자.
Sparse network and dense matrix¶
Google이 주장하기로는 Neural network는 Sparse해야 좋은 성능을 내지만 (예: Dropout), 실제 컴퓨터 연산 관점에서는 연산할 Matrix가 Dense 해야 Resource 손실이 적다고 한다 (Data가 Uniform distribution을 가져야 함).
이와 관련된 연구가 Arora가 작성한 “Provable Bounds for Learning Some Deep Representations” 논문에서 언급되었다고 한다. Arora는 전체적으로 Network 내 연결을 줄이면서 (Sparsity), 세부적인 행렬 연산에서는 최대한 Dense 한 연산을 하도록 처리했다고 한다. Google에서는 Arora 논문에서 언급된 이 2가지 개념을 반영하여 Inception 모듈을 만들었다고 한다. 자세한 내용은 논문에서 확인할 수 있다 (추후 정리 예정).
NIN¶
보통 CNN에서는 Convolution 연산을 통해 이미지 또는 Feature map의 Width (W)와 Height (H)의 크기는 줄이고 Channel (C)는 늘리는 형태를 취한다. Max pooling은 W와 H를 줄이는 역할을 한다. 이 때, 1x1 Convolution 연산으로 C를 줄일 수 있고, 그 결과 C 단위로 Fully-connected 연산하여 C 또는 차원을 줄이는 효과 (압축) 를 얻을 수 있으며, 이는 학습해야 할 Parameter 수의 감소로 이어진다.
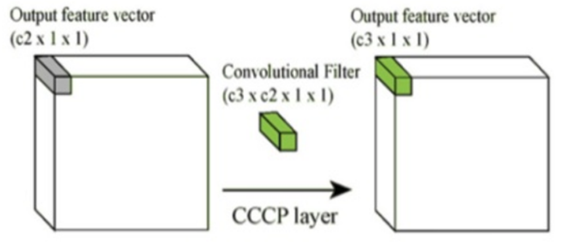
결국, 1x1 Convolution으로 Channel 수를 줄여 Parameter 수를 줄이는 것이 NIN의 핵심 내용이다. GoogLeNet에서는 이를 반영하여 Inception을 만들었다. Network in Network (NIN)에 대한 자세한 내용은 여기 에서 확인할 수 있다.
Inception¶
Google 연구팀은 NIN을 기반으로 Network를 깊게 만들면서도 연산량의 수가 급격히 늘지 않는 Inception이라는 모듈을 만들었다. 또한, Local receptive field에서 더 다양한 Feature를 추출하기 위해 여러 개의 Convolution을 병렬적으로 사용 했다.
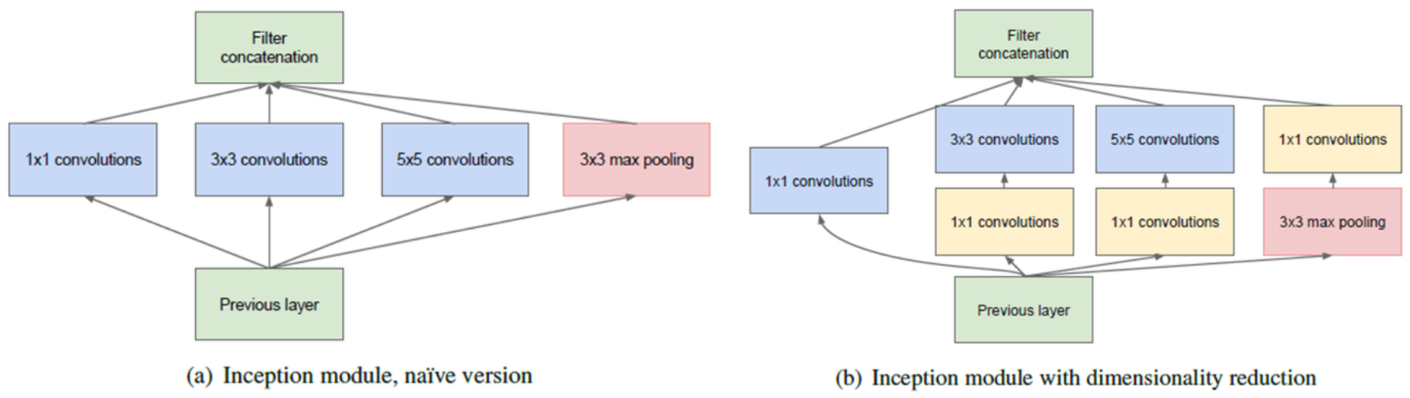
원래 초기 Inception은 상단 좌측 그림처럼 1x1/3x3/5x5 Convolution, 3x3 Max pooling을 나란히 놓는 구조를 만들었다. 이는 같은 Layer에 다른 크기를 가지는 Filter를 적용하여 다른 Scale의 Feature를 추출할 수 있게 한다.
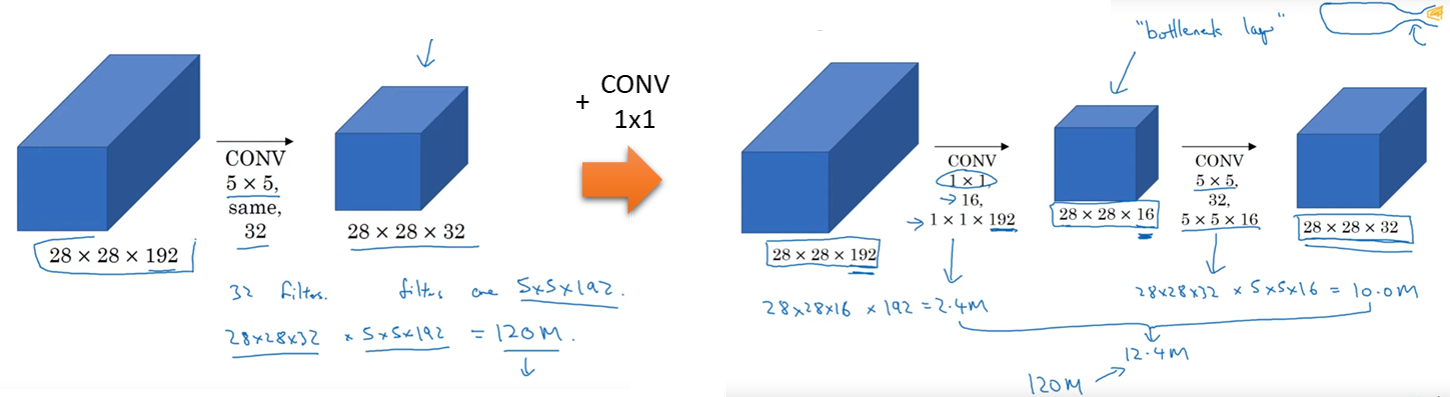
출처: YouTube, Inception Network Motivation
하지만 3x3과 5x5 Convolution은 연산량이 많아 Network가 깊어지면 치명적인 문제가 될 수 있다. 위 그림에서 볼 수 있듯이 5x5 Convolution 사용 시 약 120M 번의 연산을 해야하는데, 1x1 Convolution을 추가하면 1/10 정도의 연산인 12.4M 번만 연산하면 된다. 1x1 Convolution을 사용하면 중간 Feature map의 개수가 줄어든 모양을 일컬어 Bottleneck layer라고 부르기도 한다.
그래서 Inception 모듈에는 연산량을 줄이기 위해 1x1 Convolution으로 Feature map의 차원 수를 줄였다. 추가로 여기서 Feature map의 크기를 줄여 성능이 떨어질 수도 있다고 생각할 수 있는데, 그래서 적절한 개수의 1x1 Convolution을 사용하는 것이 중요하다.
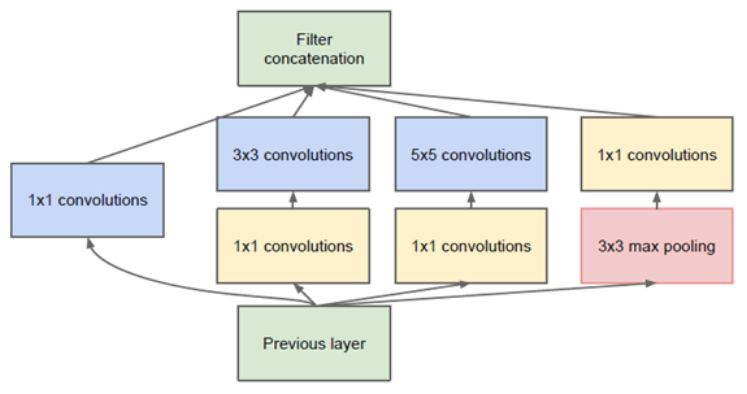
또한, 위 그림에서도 불 수 있듯이 다른 Layer와 다르게 Max pooling이 있는 Layer에서는 1x1 Convolution 보다 Max pooling을 먼저 실시한다. 그 이유는 Max pooling이 Feature map의 개수 (Channel 수)를 조정할 수 없기 때문이라고 한다.
이처럼 GoogLeNet의 Inception은 기존 CNN 구조에서 크게 벗어나지 않으면서 NIN의 특징을 반영했다 (반면 NIN은 MLP로 Non-linear feature를 얻었으나, 결국 Fully connected 형태이고 구조적으로도 익숙하지 않음).
GoogLeNet¶
GoogLeNet은 지금까지 설명한 9개의 Inception으로 구성되어 있다. 다음은 GoogLeNet 그림이고, Input image 크기는 224x224x3이다.
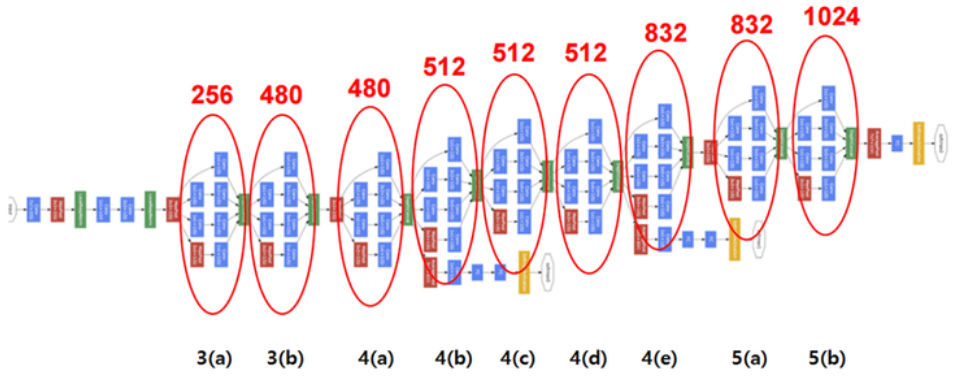
이미지에서 각 표기가 의미하는 바는 아래와 같다.
빨간 동그라미: Inception (위에 숫자: Feature map 수)
파란색 모듈: Convolutional layer
빨간색 모듈: Max pooling
노란색 모듈: Softmax layer
녹색 모듈: 기타 Function
그림에서 볼 수 있듯이 Layer 초반에는 Inception을 사용하지 않고, 일반적인 CNN에서 보이는 단순한 Conv-Pool 구조를 가진다. Inception을 사용하지 않는 이유는 Google팀에서 실험했을 때 초반에 Inception을 배치했을 때 효과가 없었기 때문이라고 하고, 논문에서는 이 영역을 Stem 영역이라고 부른다.
아래 표가 GoogLeNet의 상세한 구조와 Paramter를 정리해 놓은 것이다. 복잡해 보이지만 이를 통해 그 구조를 정확히 이해할 수 있다.
Type |
Patch size / Stride |
Output size |
Depth |
#1x1 |
#3x3 reduce |
#3x3 |
#5x5 reduce |
#5x5 |
Pool / Proj |
Params |
Ops |
|---|---|---|---|---|---|---|---|---|---|---|---|
convolution |
7x7 / 2 |
112x112x64 |
1 |
― |
― |
― |
― |
― |
― |
2.7K |
34M |
max pool |
3x3 / 2 |
56x56x64 |
0 |
― |
― |
― |
― |
― |
― |
― |
― |
convolution |
3x3 / 1 |
56x56x192 |
2 |
― |
64 |
192 |
― |
― |
― |
112K |
360M |
max pool |
3x3 / 2 |
28x28x192 |
0 |
― |
― |
― |
― |
― |
― |
― |
― |
inception (3a) |
― |
28x28x256 |
2 |
64 |
96 |
128 |
16 |
32 |
32 |
159K |
128M |
inception (3b) |
― |
28x28x480 |
2 |
128 |
128 |
192 |
32 |
96 |
64 |
380K |
304M |
max pool |
3x3 / 2 |
14x14x480 |
0 |
― |
― |
― |
― |
― |
― |
― |
― |
inception (4a) |
― |
14x14x512 |
2 |
192 |
96 |
208 |
16 |
48 |
64 |
364K |
73M |
inception (4b) |
― |
14x14x512 |
2 |
160 |
112 |
224 |
24 |
64 |
64 |
437K |
88M |
inception (4c) |
― |
14x14x512 |
2 |
128 |
128 |
256 |
24 |
64 |
64 |
463K |
100M |
inception (4d) |
― |
14x14x528 |
2 |
112 |
144 |
288 |
32 |
64 |
64 |
580K |
119M |
inception (4e) |
― |
14x14x832 |
2 |
256 |
160 |
320 |
32 |
128 |
128 |
840K |
170M |
max pool |
3x3 / 2 |
7x7x832 |
0 |
― |
― |
― |
― |
― |
― |
― |
― |
inception (5a) |
― |
7x7x832 |
2 |
256 |
160 |
320 |
32 |
128 |
128 |
1072K |
54M |
inception (5b) |
― |
7x7x1024 |
2 |
384 |
192 |
384 |
48 |
128 |
128 |
1388K |
71M |
avg pool |
7x7 / 1 |
1x1x1024 |
0 |
― |
― |
― |
― |
― |
― |
― |
― |
dropout (40%) |
― |
1x1x1024 |
0 |
― |
― |
― |
― |
― |
― |
― |
― |
linear |
― |
14x14x480 |
1 |
― |
― |
― |
― |
― |
― |
1000K |
1M |
softmax |
― |
14x14x480 |
0 |
― |
― |
― |
― |
― |
― |
― |
― |
위 표의 컬럼들의 의미는 다음과 같다.
컬럼명 |
의미 |
|---|---|
Patch size / Stride |
Filter의 크기와 Stride 값 |
Output size |
Convolution 후 생성되는 Feature map 크기 및 개수 |
Depth |
연속적인 Convolution 수 |
#1x1, #3x3, #5x5 |
1x1, 3x3, 5x5 Convolution을 의미하고, 쓰여진 값은 1x1, 3x3, 5x5 Convolution 후 생기는 Feature map 개수 |
#3x3 reduce, #5x5 reduce |
3x3 또는 5x5 Convolution 앞에 있는 1x1 Convolution을 의미하고 이를 통해 Feature map의 차원을 축소시킴 |
Pool / Proj |
3x3 Max pooling과 1x1 Convolution이 적용된 부분을 의미 |
Params |
해당 Layer의 Trainable parameters를 의미 (입출력 Feature map 수에 비례) |
Ops |
각 Layer에서의 연산 수를 의미 (마찬가지로 입출력 Feature map 수에 비례) |
이렇게만 설명하면 이해가 잘 안된다. 그래서 실제 inception (3a)를 통해 Inception 흐름을 살펴보자.
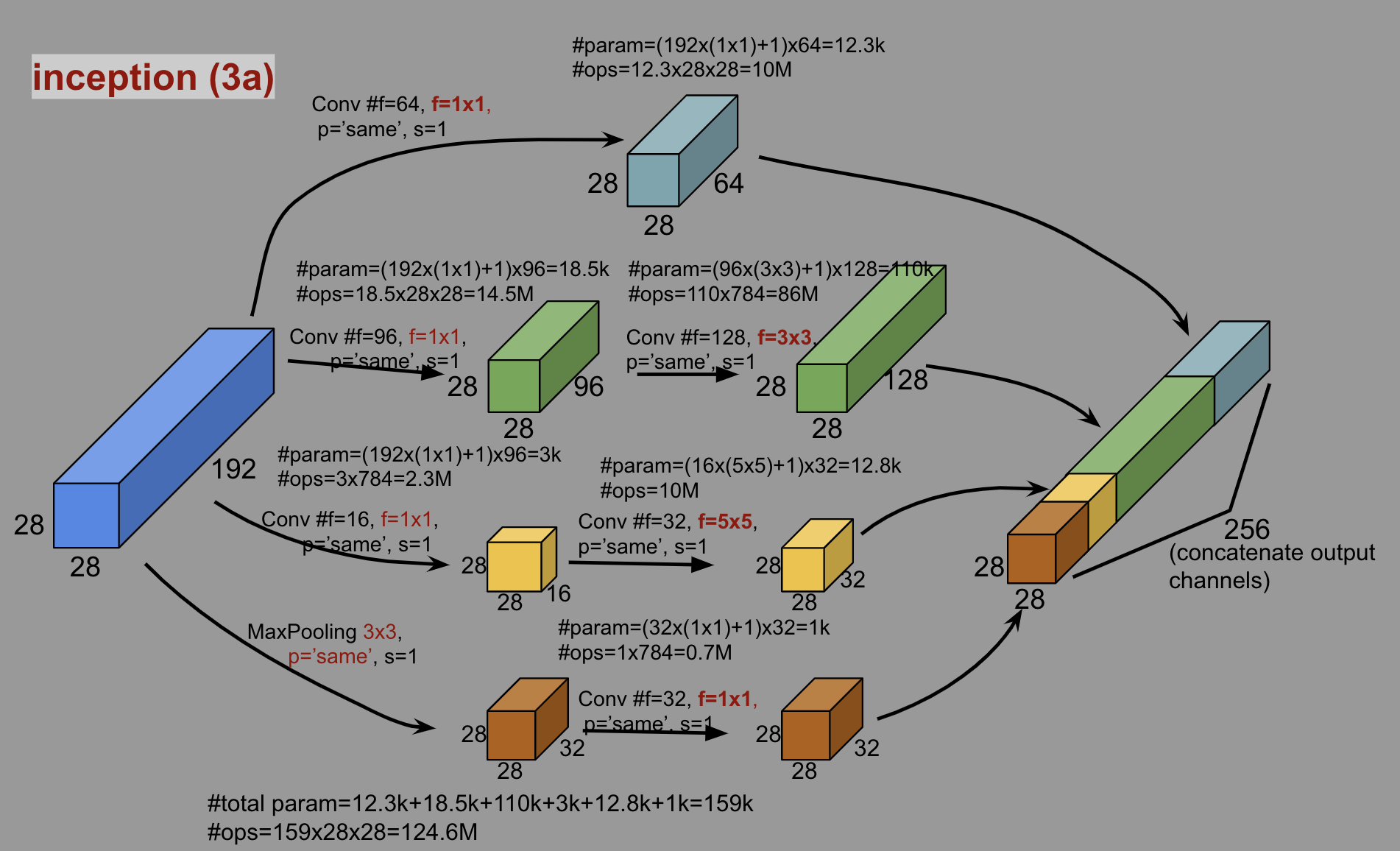
출처: Medium, Paper Review and Model Architecture for CNN (VGG, Inception, ResNet)
inception (3a)에서는 이전 Max pooling의 결과로 생성된 192개의 28x28 Feature map에서 4가지 방법으로 Feature를 추출한다.
1x1 Convolution
28x28 Feature map을 64개 생성
1x1 Convolution → 3x3 Convolution
1x1 Convolution: 28x28 Feature map 96개 생성
3x3 Convolution: 28x28 Feature map 128개 생성
1x1 Convolution → 5x5 Convolution
1x1 Convolution: 28x28 Feature map 16개 생성
5x5 Convolution: 28x28 Feature map 32개 생성
3x3 Max pooling → 1x1 Convolution
3x3 Max pooling: 28x28 Feature map 32개
1x1 Convolution: 28x28 Feature map 32개
이렇게 생성한 Feature map들을 Concatenate 해 28x28 Feature map 256개를 생성하게 된다. 나머지 inception (3b) ~ inception (5b)도 이와 마찬가지 형태로 전개된다고 보면 된다. 아까 inception (3a)에서 보면 Convolution에 앞서 1x1 Convolution 작업을 하는 것을 볼 수 있다. 1x1 Convolution은 왜 하는 걸까?
Inception 모듈에서 사용되는 1x1 Convolution은 실제로 연산량을 크게 줄여준다. inception (3a)의 1x1 and 3x3 Convolution 부분에서 보면, 1x1 Convolution으로 Feature map이 192개에서 96개로 줄어 약 50% 정도의 연산량 감소를 가져온다. 1x1 and 5x5 Convolution의 경우, 192개에서 16개로 줄어 약 91.7%의 연산량을 줄일 수 있다.
추가로 3x3보다 5x5 Convolution의 결과로 얻는 Feature map 수가 작은 이유는 기본적으로 3x3이 크기가 작아 얻을 수 있는 정보가 더 많기 때문이다. 또한, 3x3보다 5x5에서 필요로 하는 연산량이 훨씬 많기 때문에 3x3 Convolution 결과의 Feature map 수가 더 작다 (이해 X).
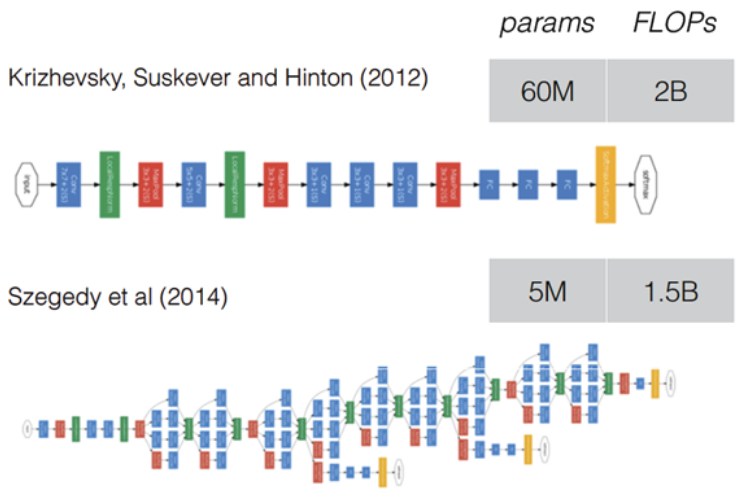
Auxiliary classifier¶
GoogLeNet에 기존 CNN에서 사용하지 않았던 새로운 구조가 더 있다. 이는 Auxiliary Classifier (AuxClf)이고, 아래 그림에 표시된 부분이다.
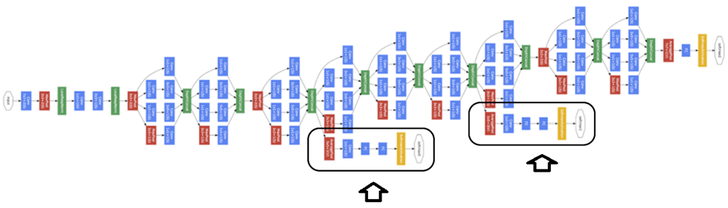
이는 Vanishing gradient 문제를 해결하기 위해 만들어진 구조이다. 조금 더 자세한 내용은 아래 논문에서 확인할 수 있다. 특히 두 번째 논문이 조금 더 체계적으로 참고하고 있으므로 확인하면 좋을 것 같다.
우선, Leiwei 논문에 나오는 AuxClf를 먼저 이해해보자.
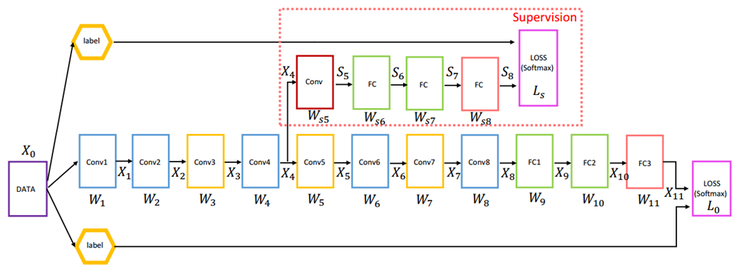
위 그림에서 X4의 위치에 Supervision이라 부르는 AuxClf를 배치하고, Back propagation 시 X4 위치에서 AuxClf의 결과와 원래 Back propagation 결과를 결합 시킨다. 이 방법으로 X4 위치에서 Gradient가 작아지는 문제를 해결 할 수 있다.
GoogLeNet에서 AuxClf의 정확한 위치를 언급하지는 않았지만, 10 ~ 50번 Iteration에서 Gradient의 움직임을 파악한 후 그 위치를 결정하는 것이 좋다고 언급했다.
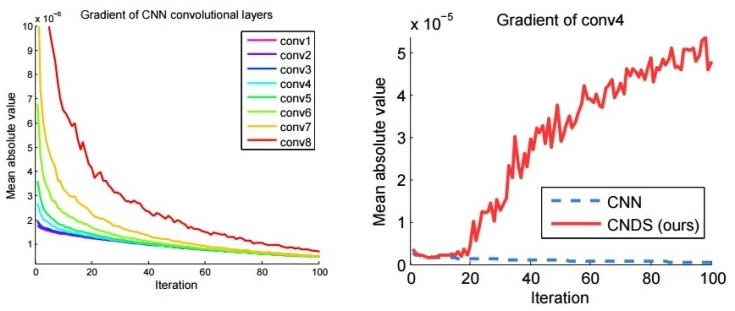
위 그림에서 좌측 그림 (AuxClf X)에서 보면 X4 (conv4)와 그 다음 Layer에서 Gradient가 현저하게 떨어지는 경향을 보인다. 오른쪽 그림에서는 CNN (AuxClf X)은 Gradient가 0에 근접하여 학습이 더 진행되지 않지만, CNDS (AuxClf O)는 Gradient가 다시 증가하여 보다 학습이 안정적으로 진행되는 것을 알 수 있다.
2015년 후반에 GoogLeNet의 첫 번째 저자 Szegedy의 논문 “Rethinking the Inception Architecture for Computer Vision”에서, AuxClf는 Regularizer 역할을 하며 Batch normalization 또는 Dropout layer를 가지는 경우 성능이 조금 더 좋아진다고 언급했다.
그리고 AuxClf는 학습 시에만 사용되고, Test 할 때는 제거한다 (학습을 도와주기 위한 용도로만 사용).
Advanced GoogLeNet¶
2014년 ILSVRC에서는 GoogLeNet이 ZFNet보다 성능이 2배 이상 좋았지만, 1년 후 2015년에 Microsoft가 GoogLeNet 성능보다 2배 좋은 ResNet으로 우승한다. 그 이후 기존 GoogLeNet을 개선한 Inception-V2, Inception-V3이 나왔고, 이 모델들은 3x3 Convolution만 사용하는 VGGNet에서 많은 힌트를 얻은 것으로 보인다. 자세한 내용은 새로운 페이지에서 설명하려고 한다.